
Dealing With Huge MediaRecorder Chunks
A more technical blog post.
We've been monitoring the size of the chunks made available through MediaRecorder's ondataavailable function for a while. For example, with a timeslice of 200ms, these chunks should contain data amounting to roughly 1/5th of a second, so they shouldn't be too large. Indeed, most chunks are small (approximately 75KB for 200ms of 1080p H.264 video through Chrome), but we constantly saw larger chunks, some as large as 50MB, from vanilla browsers (Chrome on Windows, etc.).
Now, your app's reaction to such large slices might vary. They might go unnoticed, or you might get a 413 (Request Entity Too Large) error from Nginx which has a default value for client_max_body_size of 1 megabyte (MB).
We push these chunks to our ingestion servers through socket.io and, by default, the maximum amount of data it allows in a websocket message is 1MB or 1000000 bytes (the setting is called maxHttpBufferSize). Because the larger chunks were above our limit they were rejected. This pushed our desktop recording client into an infinite loop:
- the chunks were rejected server side by socket.io
- socket.io closed the websocket connection,
- our desktop recording client attempted to re-connect
- the new connection went through
- the large chunk was still in the local buffer marked as unsent
- large chunk is picked up to be sent through the active websocket connection only to be rejected again
Several questions arose:
- what causes it?
- can we fix it?
- is there valuable data in the chunk?
To find out, we've updated our MediaRecorder demo to display the size in bytes of each chunk, the onmute, onunmute, and onended events, the recording timecode, and began testing.
Eventually, we were able to generate large and very large chunks in 3 ways, detailed below. There might be other ways.
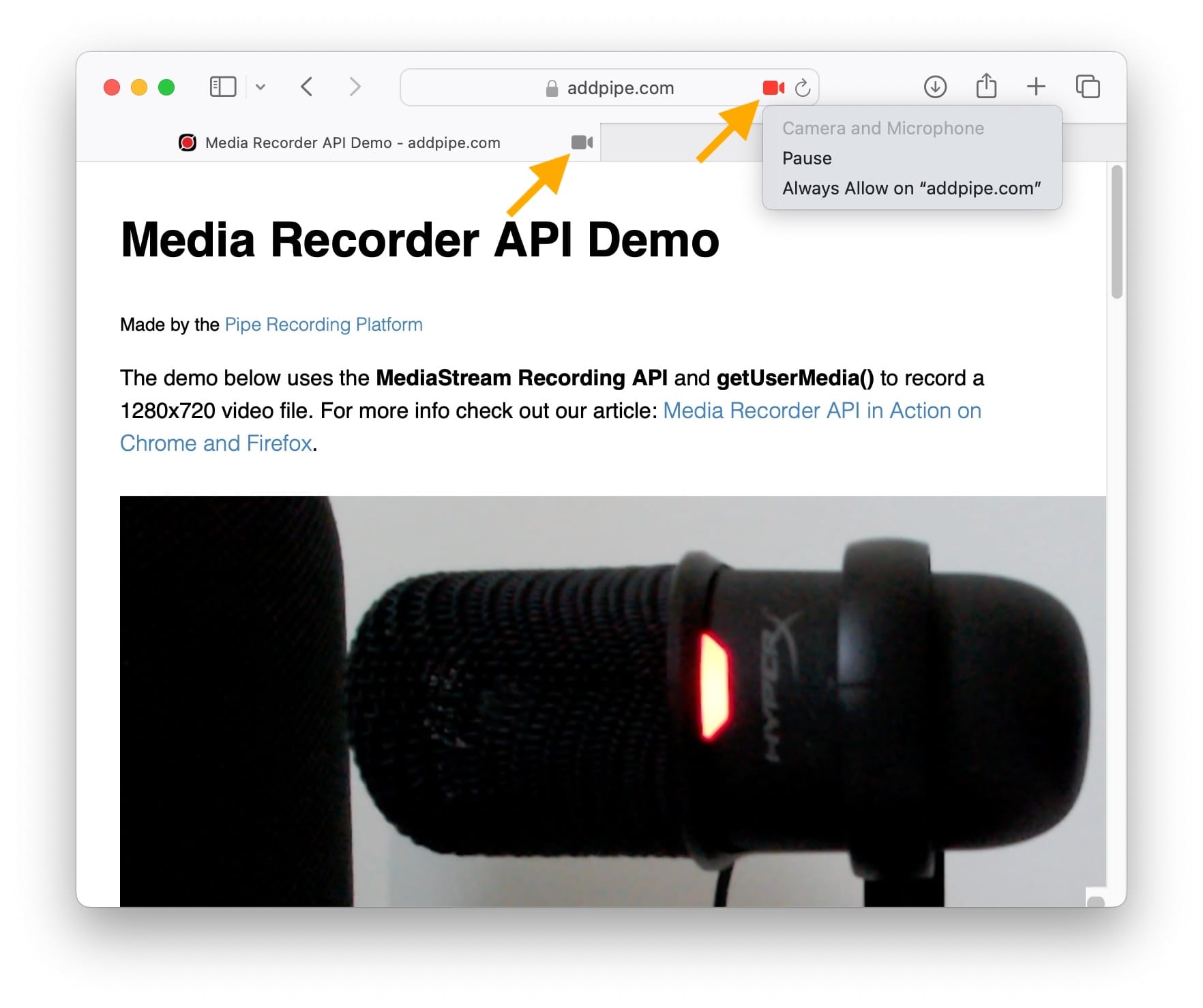
1) Pause and resume camera access on Safari on macOS/iOS
Safari, across macOS and iOS, has easily accessible UI elements that allow users to pause and resume access to the "Camera and Microphone". Using these UI elements results in track.onmute and track.onunmute being called on both the audio and video tracks but also results in a few larger chunks showing up through ondataavailabe immediately after resuming/umuting (as if having to empty a local buffer). ondataavailabe is called with 0 data while the devices are paused.
With this method, I could easily generate chunks 15x, the size of a normal chunk. A quick inspection with ffprobe -show_frames video.mp4 reveals a continuous stream of audio frames for the paused period but no video frames.
This is a bug as the final recording does not have and should not have any (audio) data for the period of time during which camera and mic access has been paused. We've opened a WebKit bug report about it which contains a bit more details.
We've tested with Safari 17.6 on macOS Sonoma 14.6.1 and Safari on iOS 17.6.1.
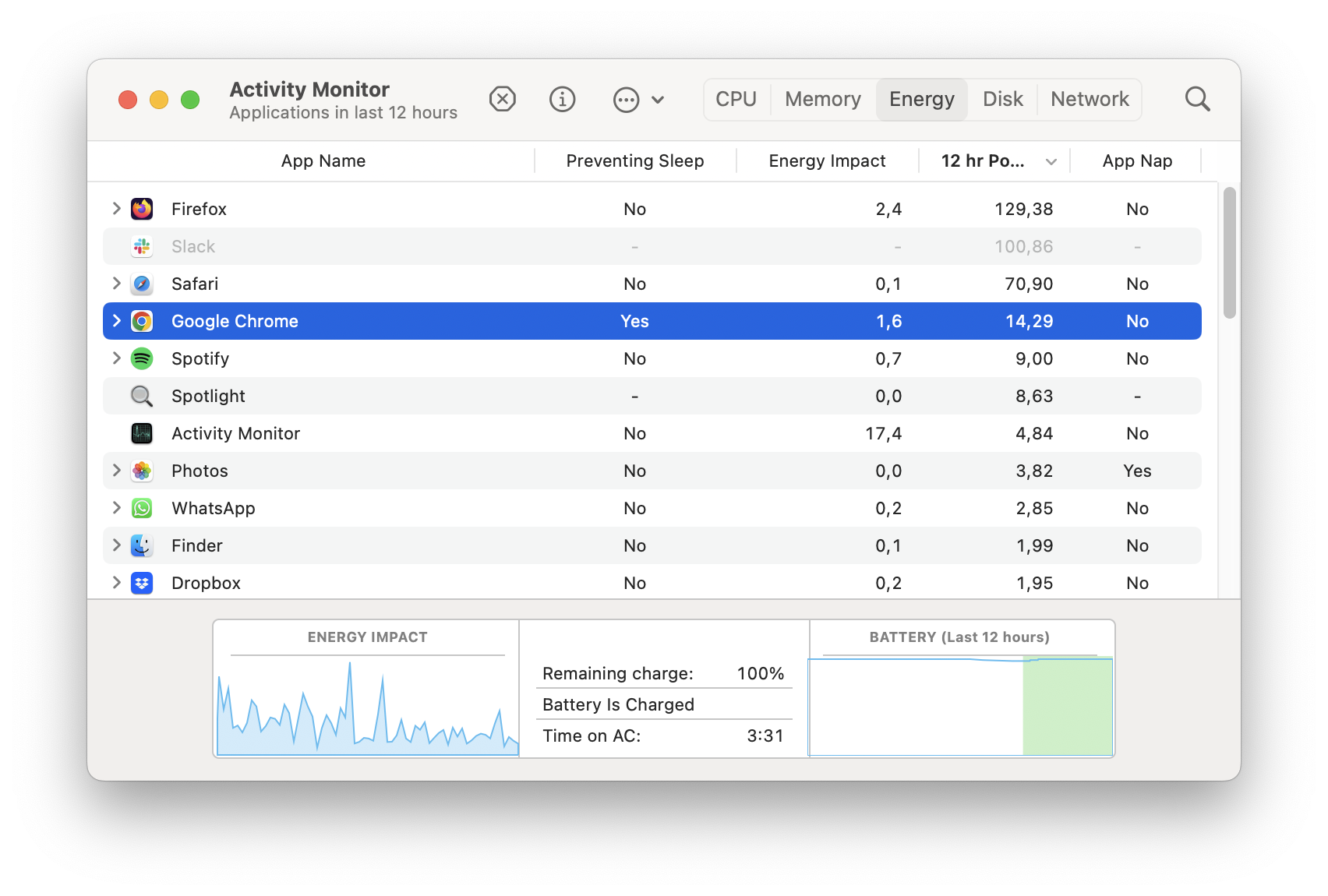
2) Sleeping the computer while recording with Chrome on macOS/Windows
If, while recording, the computer you're on enters sleep mode (we've either closed the lid or used the Sleep option in the OS menus), then wakes up, when you eventually stop the recording, you'll get two new ondataavailable calls with one of them containing a very big chunk.
There's a few issues with this scenario:
- on wake up
ondataavailableis not fired anymore (it is on Chrome on Android, see below) - the scenario can't be totally accurately reproduced across different machines; there's variations.
Clearly a buggy scenario. We've reported the bug in the Chromium issue tracker including a detailed log for when we managed to create a 23MB chunk.
Recording content, as extracted with ffprobe -show_frames differs between variations.
3) Locking the screen with Chrome on Android
If you record on Chrome on Android and lock the phone, the recording switches from audio+video to audio only while the video track mutes. When you unlock the phone, the video track unmutes, and there's a big chunk made available through ondataavailabe (probably containing all the audio data captured while the phone was locked). I was able to generate a 15MB chunk by recording 20 minutes with the phone locked.
The final recording has three sections: (1) video + audio (2) audio only while the screen was locked and (3) video + audio. The recording plays back correctly.
This also happens if you receive a phone call or switch apps while recording,
This behavior does not feel buggy in any way so these big chunks are here to stay. We'll have to find a workaround!
We've tested with a Google Pixel 4a and Chrome 128 on Android 13.
Solutions
Even if someone immediately fixes the Chrome and Safari bugs above, we still need a way to account for the large slices created by Chrome on Android (scenario 3 above).
Increasing the maxHttpBufferSize value seems like the immediate solution, but it doesn't feel like a true fix, more like we're pushing the threshold past which we have a problem.
Eventually, we ended up splitting the bigger chunks into smaller ones locally, in the browser, using Blob.slice(). This workaround is here to stay. A new desktop recording client build containing this fix was rolled out recently.
Another solution - which we have not explored - could involve actively calling MediaRecorder.requestData().
Conclusion
The size and duration of a recording slice received through ondataavailable can vary a lot.