
Using Gearman in 2022
We're using Gearman to process tens of thousands and hundreds of thousands of recordings per day.
This is the summary of work & research done by all 3 engineers at Pipe: Octavian, Remus and Cristian.
This blog post is written as a note to our future selves and in the hope that it might save someone else some time and aggravation.
Here's what we learned.
Admin tools
There are two admin tools that ship with Gearman:
- an administrative protocol which you can use by TELNETTing into the running
gearmandservice and typing text commands - the
gearadmincommand-line which is mostly a wrapper for the admin protocol.
Gearmand supports a very simple administrative protocol that is enabled on the same port used by GEAR. You can make use of it via the gearadmin tool.
The gearmand TEXT protocol
On a machine running the Gearman daemon you can telnet localhost 4730 and issue text based commands. You can get the Gearman version number, show all current jobs and their unique id, get the status of all current jobs and a bunch of other stuff.
Most commands are documented here, but since that file might not be up to date, you'll find the complete list of commands and their arguments in the source code. There's also more info in the PROTOCOL document's Administrative Protocol section.
Here's the output of the status command with my annotations.
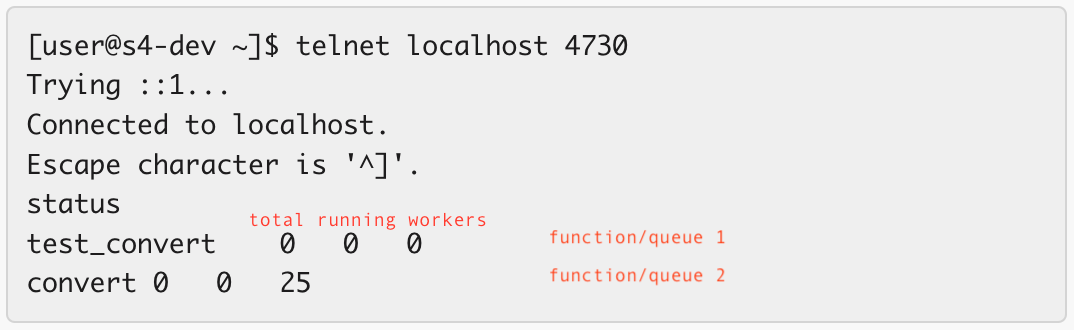
Both gearadmin - mentioned below - and the Gearman exporter - also mentioned below - will read the info by connecting to the Gearman daemon (gearmand).
Gearadmin
Gearadmin is mostly an interface for the above administrative text protocol. There's wide parity between the two with only the maxqueue command in the admin protocol not being available through gearadmin.
Here's the output of gearadmin --help on a machine running a self-compiled post 1.1.19.1 version of Gearman:
[user@dev ~]# gearadmin --help
Options:
--help Options related to the program.
-h [ --host ] arg (=localhost) Connect to the host
-p [ --port ] arg (=4730) Port number or service to use for connection
--server-version Fetch the version number for the server.
--server-verbose Fetch the verbose setting for the server.
--create-function arg Create the function from the server.
--cancel-job arg Remove a given job from the server's queue
--drop-function arg Drop the function from the server.
--show-unique-jobs Show unique IDs of jobs on the server.
--show-jobs Show all jobs on the server.
--getpid Get Process ID for the server.
--status Status for the server.
--priority-status Queued jobs status by priority.
--workers Workers for the server.
-S [ --ssl ] Enable SSL connections.
And, for posterity, here's the output of some of these options:
[user@dev ~]# gearadmin --getpid
122020
[user@dev ~]# gearadmin --status
convert 2 2 25
.
[user@dev ~]# gearadmin --show-unique-jobs
b46a91a2-d4fd-11ec-a3bd-fa86f9a96738
b265e58c-d4fd-11ec-a3bd-fa86f9a96738
.
[user@dev ~]# gearadmin --show-jobs
H:dev.microptest.com:2 0 0 1
H:dev.microptest.com:3 0 0 1
.
[root@dev ~]# gearadmin --priority-status
convert 0 0 0 25
Gearman Exporter for Prometheus
There's a rather well maintained Gearman metrics exporter for Prometheus. It'll export the total/running/waiting number of jobs per function/queue and the number o workers per queue/function. Seeing their evolution in Grafana through Prometheus is quite useful.
Here's a handy Grafana dashboard for the data.
Several Changelogs
There are four changelogs:
- the ChangeLog file in the repo, which was updated until 2014
- the ChangeLog file in the last release , which is different from the one in the repo, has unsorted changes and does not group together the changes past the 1.1.14 tag/version
- the release notes on GitHub with not much in them
- the list of commits on GitHub into the master branch seems to be the ultimate source of truth
Priorities inside a queue/function
The HIGH, NORMAL, and LOW priorities available in Gearman are per function. If you think of these Gearman functions as queues, separate queues, it makes more sense.
So, suppose you only have one function/queue in your implementation and use all three priorities. In that case, Gearman will work as expected and assign the queued jobs to workers in the priority order.
Suppose in your implementation you have multiple functions, and you need to use the Gearman priorities. In that case, you can simplify by refactoring the code to use the same function name (so that the prioritization part works across your jobs) and send the actual function that you want to execute through the workload data.
The above is well covered in this talk on job queues with Gearman at the SoFloPHP Miami Meetup - November 2014 (seek to 34:24).
Visibility into the queue structure
The number of jobs with each priority per each function/queue is not yet available through the Gearman metrics exporter for Prometheus, only the total/running/waiting values per function/queue. We've opened a ticket about adding the metric.
The administrative protocol discussed above, used by the exporter for other metrics, has the queue structure information for waiting/not running jobs through the prioritystatus command, but, from our experience, it is bugged. It does not return the expected/correct values. We've opened a ticket about the issue here. Update: the issue was fixed, and the 1.1.20 release of Gearman will contain the fix.
Such an export would have given us immediate visibility into the queue structure (in terms of priority) through Prometheus and Grafana. This structure is important when you have a backlog of tens of thousands of jobs with different priorities that are waiting to be picked up by available workers.
As a result we've explored other ways to gain visibility into the queue structure. One promising idea was to use a persistent queue in MySQL or SQLite. You'll have access to the queue_gearman table which has a priority column of type INTEGER. You'll be able to SELECT priority, COUNT(*) from queue_gearman GROUP BY priority and push the data to a separate timeseries table for display in Grafana.
Priorities between queues/functions
Now, if you have an implementation where you need to use both multiple queues and multiple Gearman priorities, you need to understand in what order jobs from different queues are assigned to workers. There's a clue in the gearmand -h docs. They mention the -R option, which switches the Gearman daemon from assigning work "in the order of functions added by the worker" to "round-robin order per worker connection."
It would seem that, by default, workers would pick up jobs from the 1st function/queue they added. We've tested this, and we confirmed this mechanism.
This allows us to start 30 workers, which 1st register for picking jobs from the copyFilesForPROAccounts queue/function and then register for copyFilesForTrialAccounts as a 2nd queue/function. All 30 will work on the 1st queue/function (copyFilesForPROAccounts) before moving on to the 2nd. As a result, your copyFilesForPROAccounts jobs will be processed 1st.
This way of prioritizing jobs works across several functions so if you need more than the 3 priorities built-in Gearman, using different functions instead of Gearman priorities might be a worthwhile approach.
Things get a bit more complicated when you have a different number of workers for each function/queue.
Managing (PHP) workers
Supervisor seems to be the default go-to tool for managing (PHP) workers. It is written in Python, and it is well maintained. It allows you to start & stop individual workers and groups of workers as needed.
You should also consider GearmanManager . It can "monitor the worker dir and restart the workers if it sees new code has been deployed to the server" and "when shutting down GearmanManager, it will allow the worker processes to finish their work before exiting."
Dynamic number of workers
Should you need to scale up or down the number of workers, you could use Supervisor to start/stop more workers or groups of workers. On the Node/JS side pm2 has pm2 scale +2.
Deduplication of jobs
German will deduplicate jobs that have the same unique id. You can specify your own unique id (like a recording id) for each job when sending a job to Gearman. If you don't, Gearman will generate one for you.
Here's a sample of how the Gearman generated ids look:
b46a91a2-d4fd-11ec-a3bd-fa86f9a96738
b265e58c-d4fd-11ec-a3bd-fa86f9a96738
ac9db288-d4fd-11ec-a3bd-fa86f9a96738
aed2e348-d4fd-11ec-a3bd-fa86f9a96738
56b20ed2-d4fd-11ec-9612-fa86f9a96738
The deduplication works per function/queue.
From our testing, it seems that if you push to Gearman several jobs with the same unique id but different priorities, the (one) job inside Gearman will inherit the last priority.
Background jobs
Background jobs will not block the client. Since you're not getting an immediate response with background jobs, they'll return a job handle (a string) instead. You can later use it to ask Gearman about that job's status.
Here's an example of such a job handle: H:dev.yourdomain.com:13 . Because the host part (dev.yourdomain.com) is static and the ending id is a self incrementing id, the job handle is pretty easy to store/save. Keep in mind it will only be available with background jobs.
If you give Gearman a background job with a unique id that already exists in the queue, "gearman will feed back the same job handle that’s already in the queue to the client".
Running jobs at specific times in the future.
The straightforward way to do this is by using cron jobs, the at or batch commands, or some other way to send jobs to Gearman when they're supposed to run. If the workers aren't busy, the job should be run right away. Cron jobs and the at command don't have a sub-minute resolution, but with at, you can fake it.
About when_to_run
I'm covering the epoch/when_to_run option below especially in the hope that it might save someone else some time and aggravation :).
The Gearman PROTOCOL mentions SUBMIT_JOB_EPOCH as a way to"run job at given time instead of immediately." It also mention, "This is not currently used and may be removed." But Gearman does have an implementation. Unfortunately, the functionality is not present in the Gearman PHP extension, which we used (so there is no way to access it, really), so it was not immediately visible. I believe we stumbled upon the feature when we experimented with persistent queues and found the when_to_run column in both the SQLite and the MySQL schemas for the persistent queue. The column takes Unix timestamps as a value, so it looked like it would be accurate to the second. As we'll see, it is not.
On top of the lack of accessibility to the when_to_run values, from our testing, each scheduled job needs another unscheduled job to be inserted on the same queue/function AFTER the when_to_run moment. Otherwise, the scheduled job will not be picked up by Gearman to be sent to workers. The unscheduled job worked as a trigger. This was clear from both our testing and this issue on GitHub. Thus the when_to_run value functions more like a minimum execution timestamp, with the maximum being defined by how long after the when_to_run value an unscheduled job is added to the same queue/function.
An extreme workaround for it not being accessible through the Gearman PECL PHP extension was to stop Gearman, edit the when_to_run values in the persistent queue and start Gearman. Gearman would now load the values from the persistent queue. We used this workaround during development to test the when_to_run functionality. Another workaround found on StackOverflow falls back to using cron.
Persistent queues
Persistent queues are useful because they ensure the queue is kept across Gearman restarts. Without persistence, if you have data in the queue that's not saved/stored anywhere else and you restart Gearman, that data is lost.
With some persistent queues, you'll also benefit from persistent queues across server restarts because a persistent queue in MySQL or SQLite will save the data to disk, while a Memcached powered persistent queue will not.
Another benefit is the visibility you get into the queue. With a SQLite persistent queue, you can use SQL queries to SELECT all jobs inside the queue with their function, priority, workload data, and the rather useless when_to_run timestamp. You could also COUNT or GROUP BY and extract the data where you need it.
Gearman will save to the persistent queue in addition to the internal queue. As we understand it, the internal queue remains the source of truth, and the persistent queue is just a (latent) copy. This is important because:
- changes in the persistent queue will not be read into the internal queue (if you really need to inject changes through the persistent queue, you could stop Gearman, make the change, and then start Gearman to read the changes)
- you can't use the persistent queue as a memory/RAM saving mechanism (as a side note, 10k almost empty jobs - 1 char in payload otherwise the job is invalid - takes up ~10mb of memory)
Here's the MySQL/SQLite schema with Gearman 1.1.19.1
CREATE TABLE gearman_queue ( unique_key TEXT, function_name TEXT, priority INTEGER, data BLOB, when_to_run INTEGER, PRIMARY KEY (unique_key, function_name));
gearmand -h will list the persistent queues your Gearman build supports.
Securing the connections between Gearman and the clients/workers
- limit the IPs which can connect to Gearman's port 4730 through a cloud or OS level firewall
- limit the IPs on which Gearman listens at startup
- use SSL (the client worker connections are not be encrypted by default)
Getting help
Some of the topics I have not had the chance to cover above.
So maybe in a future blog post:
- When are jobs removed from the queue? normally, when all is well, they're removed on successful job completion by a worker. But what happens if the job fails is some expected or unexpected way?
- Ways to signal Gearman that a job did not complete
- How fast you can push jobs to Gearman ? It takes a while to push tens of thousands of jobs (what we call a "cold start").
- Various other ways to dynamically change the number of jobs being executed at the same time (dynamic number of workers).
- Graceful stop of Gearman & workers